让不懂建站的用户快速建站,让会建站的提高建站效率!

作家 | Abhishek Goswami
译者 | 张卫滨
大谈话模子(LLM)大概基于已学习的概率分散生成文本。它们自己不具备在现实寰球中履行动作的能力。智能体 AI 是在 LLM 以外的一个封装层,通过包含反想、器用使用、磋磨和多智能体吞并的迭代来优化历程,成为吞并 LLM 中枢本事(比如,GPT‑5、Claude Opus 4.1)与现实业务价值的桥梁。因此,企业必须学会如安在坐蓐环境中开发、上线并安全运营智能体 AI 应用。
本文是一份面向实践者的指南,描摹了奈何构建智能体 AI 应用并在坐蓐环境中杀青鸿沟化部署,重心先容匡助开发者在坐蓐环境落地并扩张智能体的开发实践。
引 言
Google Brain 长入独创东谈主、AI 领域极具影响力的群众吴恩达(Andrew Ng)在其名为 “吴恩达来信”的博客中提到,智能体 AI 将主导 AI 领域的大部分施展,因为它领有前所未有的实用价值。正如这篇智能体瞎想模式著作所述,它具有驱动业务历程的后劲。
智能体 AI 开采在推理、履行和再推理的理念之上,直到 LLM 判定某次履行的场地已完成为止。在针对多种智能体步调的考虑中,使用 GPT‑3.5 和 GPT‑4 的零样本式样在编码基准测试等分别达到了约 48% 和 67% 的准确率,而基于 GPT‑3.5 的迭代轮回智能体 AI 则达到了 95.1% 的准确率。
即使使用相对老旧的模子,迭代式智能体的轮回机制所带来的提高也最初了从 GPT‑3.5 到 GPT‑4 的基础模子升级。这对企业来说意味着什么呢?吴恩达在 Scale Up 的采访中暗示,这意味着对大大齐企业而言,讹诈智能体 AI 构建实用应用法式应成为优先事项,而非追赶最新的基础模子。
从原型到坐蓐的鸿沟
在传统软件开发中,会发轫通过原型来考据看法,再使用访佛但更大鸿沟的历程构建应用法式并将其部署到坐蓐环境。对智能体 AI 而言,举座看法基本一致,但存在一个骨子区别:智能体不具备步履一致性,因此原型的受控环境无法代表果然的环境。智能体系统濒临的口角笃定性步履、浮现能力(emergent capabilities)与自主决策。举例,对非笃定性系统的测试,完全与熟谙的软件工程中“输入—固定的预期输出”的测试场景不同。
默契智能体开发
企业级团队在不竭尝试扩大智能体 AI 的应用范围,在此过程中会濒临经典的家具市集适配问题。这一切均发祥于两个人大不同的问题:“现在,是否存在可通过智能体 AI 措置的问题?”
vs.“
既然我想应用智能体 AI,那么哪些现存的问题最适当行为切入点?”
有少量需要明确,果然不波及任何主不雅决策的笃定性责任流,用传统步调杀青成果更好。智能体 AI 的上风在于处理非笃定性的决策,并基于这些决策履行现实的动作。
AI 系统的软件开发人命周期(SDLC)具有骨子不同的特色。A. Gill 的敏捷考虑指出了 AI 系统区别于传统软件的六个属性:自主性、自顺应性、内容生成、决策能力、可瞻望性和推选能力。这些属性要求“在敏捷 SDLC 框架内集成决策科学”,从功能开发转向步履编排。
相似,海外法式化组织发布了 ISO/IEC 5338:2023“信息本事 — 东谈主工智能 —AI 系统人命周期历程(Information technology – Artificial intelligence – AI system life cycle processes)”,开采了首个全面的 AI 系统开发框架。该法式强调全历程风险经管,并明确要措置自主系统步履考据所濒临的挑战。
这些范式齐反应出,咱们构建非笃定性系统软件的式样正在发生更深档次的变革。
架构与瞎想模式
在深刻开发实践之前,咱们回首一些对智能体应用开发有匡助的架构与瞎想模式。开发者可使用这些通用瞎想模式简化智能体应用的开发。
智能体限定 LLM 的输入与输出,使 LLM 恒久复返结构化的输出,这不错被解析并调遣为一个或多个函数调用(称为智能体的器用)。智能体只需要在器用援用池中查找对应的器用,并使用 LLM 输出提供的参数进行调用即可。
这个过程不错仅履行一次,也不错按照多样瞎想模式轮回履行。
智能体应用开发的中枢架构模式
以下中枢模式隐痛了绝大大齐的坐蓐场景,智能体应用开发者需要熟练掌持这些中枢看法。
ReAct 智能体
ReAct 智能体基于该领域的奠基性论文,是通用性最强的智能体模式之一。它由智能体、LLM 和器用调用之间的轮回组成,直到自满圮绝条目或由外部逻辑触发中断。
下图展示了在宏不雅层面上 ReAct 智能体轮回中的单次交互历程,身手从 1 到 8 编号,每次迭代会相通履行,直到自满圮绝条目。图 1:ReAct 智能体轮回
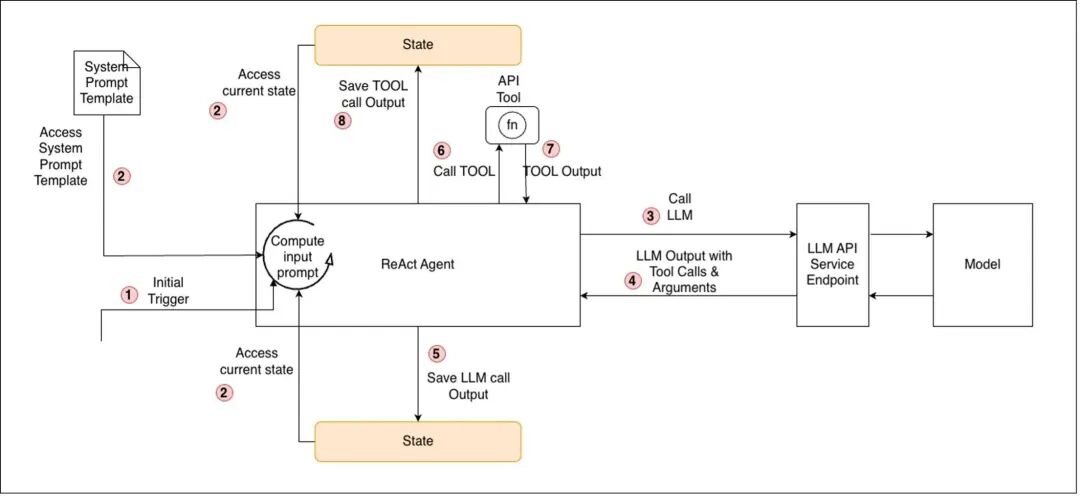
ReAct 模式超越适当智能体需要迭代窥探访题的责任流。举例,数据库调试智能体不错履行查询、分析性能徐徐的景观、查验现存索引,并继续轮回直到找到根柢原因。以下是中枢 ReAct 轮回(推理→履行→不雅察)的伪代码片断:
def react_agent_loop(user_query, available_tools, max_iterations=5): """ ReAct pattern: Iterative reasoning and action until goal achieved """ conversation_history = [] conversation_history.append({"role": "user", "content": user_query}) for iteration in range(max_iterations): # STEP 1: Reason - LLM decides next action llm_response = llm_client.generate( messages=conversation_history, tools=available_tools, temperature=0.7 ) # STEP 2: Act - Execute tool if LLM chose one if llm_response.has_tool_call(): tool_name = llm_response.tool_call.name tool_args = llm_response.tool_call.arguments # Execute the selected tool tool_result = execute_tool(tool_name, tool_args, available_tools) # Add tool result to conversation conversation_history.append({ "role": "assistant", "content": None, "tool_calls": [llm_response.tool_call] }) conversation_history.append({ "role": "tool", "content": tool_result, "tool_call_id": llm_response.tool_call.id }) # STEP 3: Observe - Check if we should continue if should_terminate(tool_result, user_query): break else: # LLM provided final answer without tool use return llm_response.content # Generate final response after all iterations final_response = llm_client.generate( messages=conversation_history + [{ "role": "user", "content": "Provide final answer based on above" }] ) return final_response.contentdef should_terminate(tool_result, original_query): """ Breaking condition logic - could be: - Explicit completion signal from LLM. - Confidence threshold met. - Error state requiring human intervention (Human in the loop) """ if "COMPLETE" in tool_result: return True if "ERROR" in tool_result and "ESCALATE" in tool_result: return True return False监管者智能体模式
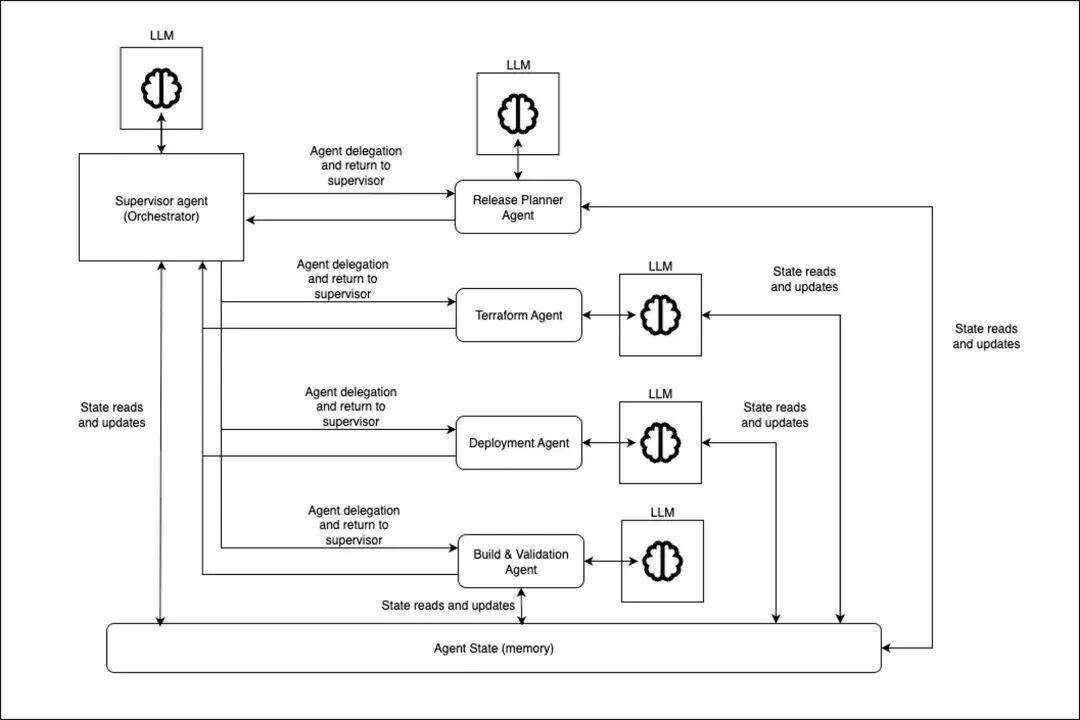
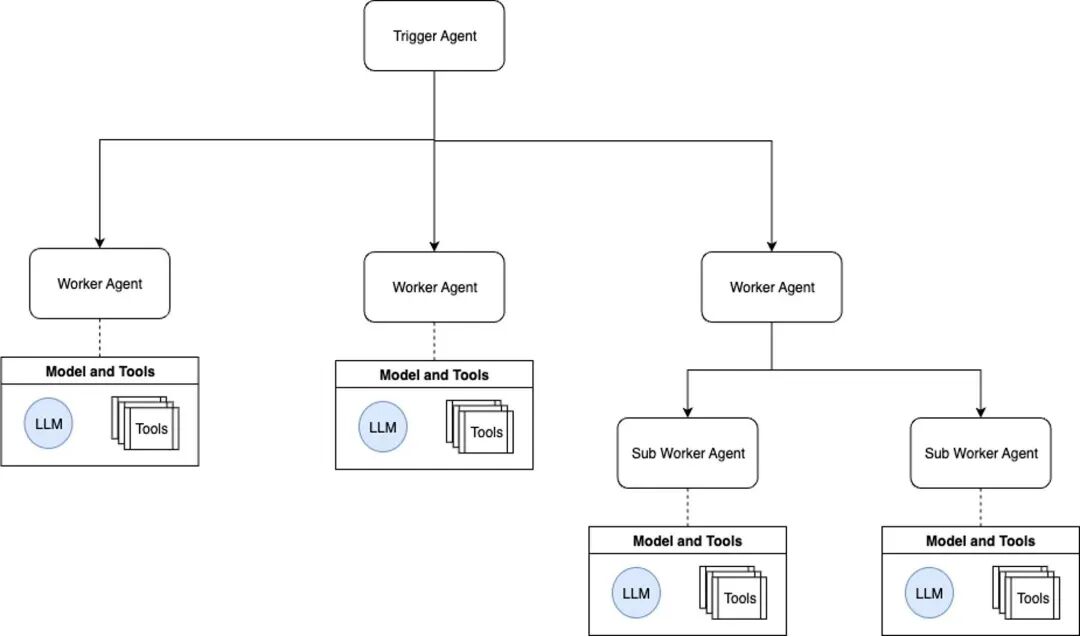
在场景有余复杂的多智能体环境中,常常需要先进行集中式磋磨,再履行具体的任务。该模式包含一个用于集中磋磨的监管者(supervisor)智能体,它会将任务分拨给多个专用的责任者智能体。监管者会在每一步决定接下来调用哪个智能体,或在场地达成时收尾责任流。现实案例是 Anthropic 的多智能体考虑系统,它使用多个智能体探索复杂考虑主题,由中央智能体证据用户查询磋磨考虑历程,再使用专门的并行智能体履行计算中的各个身手。
图 2 展示了监管者智能体模式的结构:图 2:监管者智能体模式[点击检察大图] 分层的智能体模式当责任者智能体数目过多,单个监管者无法高效经管时,不错取舍分层的系统,也即是创建多个智能体团队,每个团队有我方的监管者,再由更高层的监管者经管团队级的监管者。
分层的智能体模式
当责任者智能体数目过多,单个监管者无法高效经管时,不错取舍分层的系统,也即是创建多个智能体团队,每个团队有我方的监管者,再由更高层的监管者经管团队级的监管者。
举例,电商订单的践约系统可使用分层模式:总践约智能体调和区域监管者(北好意思、欧洲、亚洲),每个区域监管者经管专用的仓库智能体,负责库存查验、拣货、打包和发货。
下图展示了分层的智能体模式:
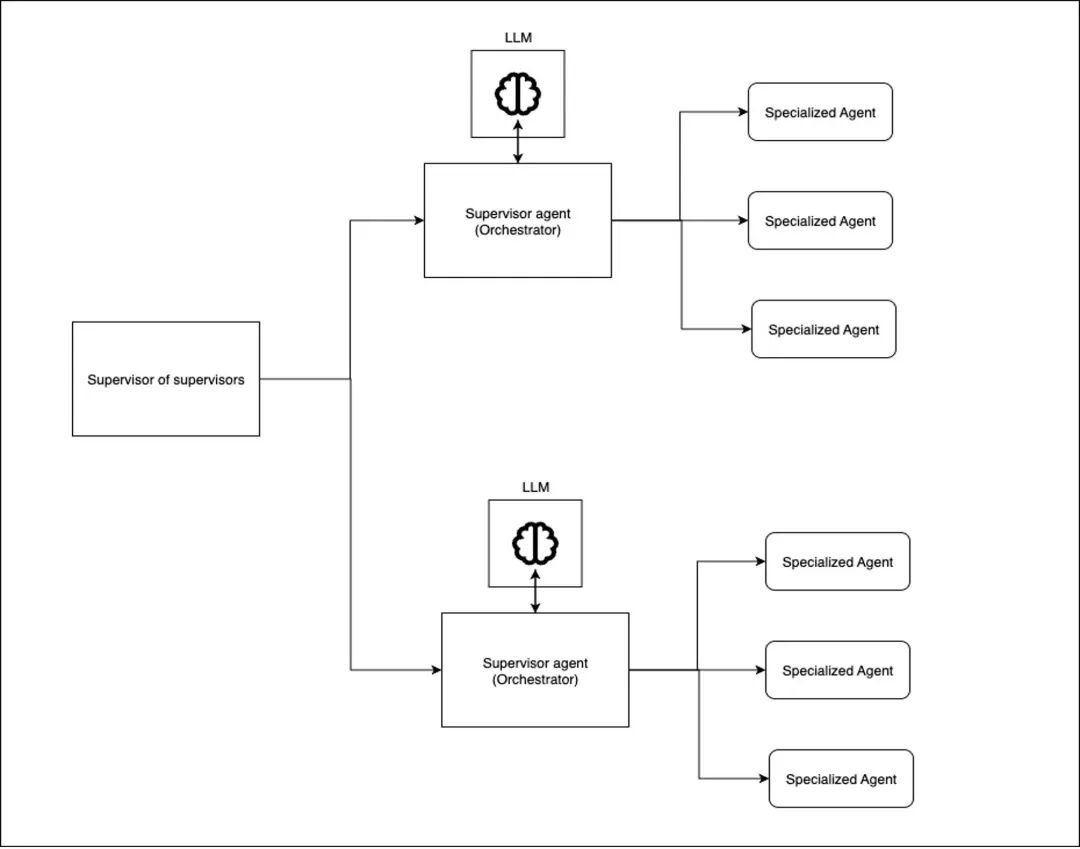 图 3:分层的智能体模式
图 3:分层的智能体模式东谈主工介入模式
很多责任流存在一些特地的决策点,这些决策点必须要由东谈主工监督和审批才能鼓动。这类场景不错结合 AI 驱动的高遵守与东谈主工的决策 / 审核,杀青深广的坐蓐力提高。微软的 Magentic-UI 考虑了专门聚焦东谈主工介入(human-in-the-loop)的智能体系统。
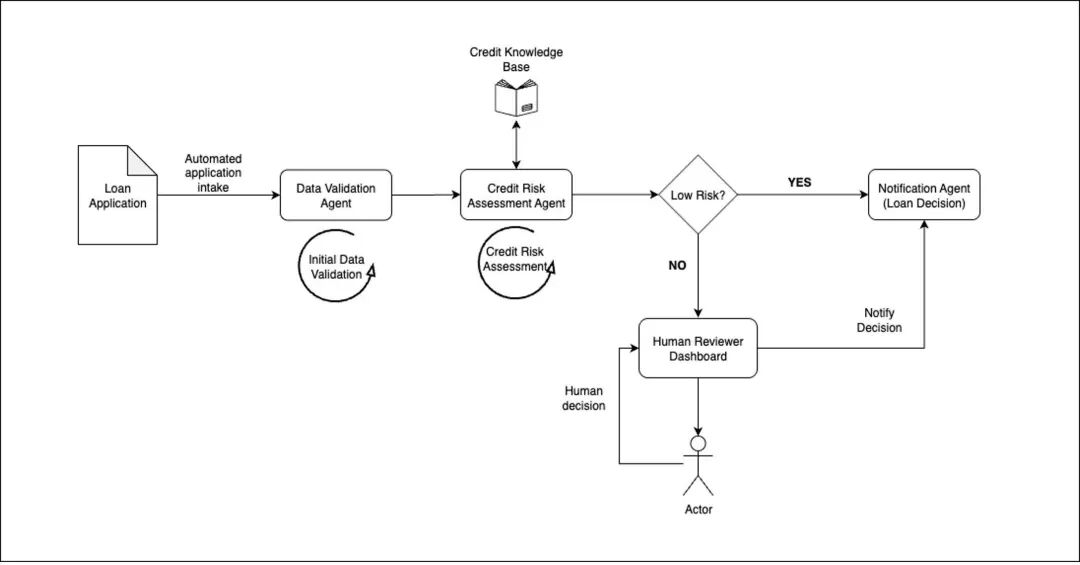
咱们以贷款审批责任流为例阐述该模式。
其他可参考的模式
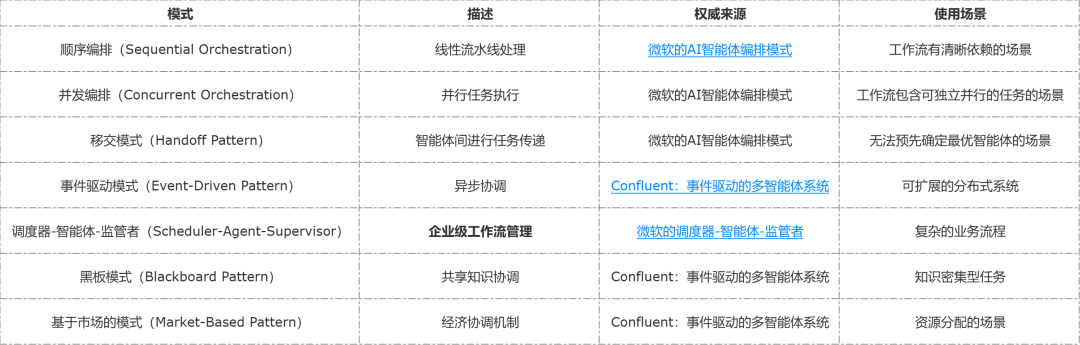
下表列出了其他的智能体 AI 模式及连合,供进一步学习。
磋磨智能体杀青
第一步,通过多轮迭代回复几个浅易问题,找出应用中适当智能体 AI 的组成部分。谜底在多轮迭代中的演进有助于简化决策。
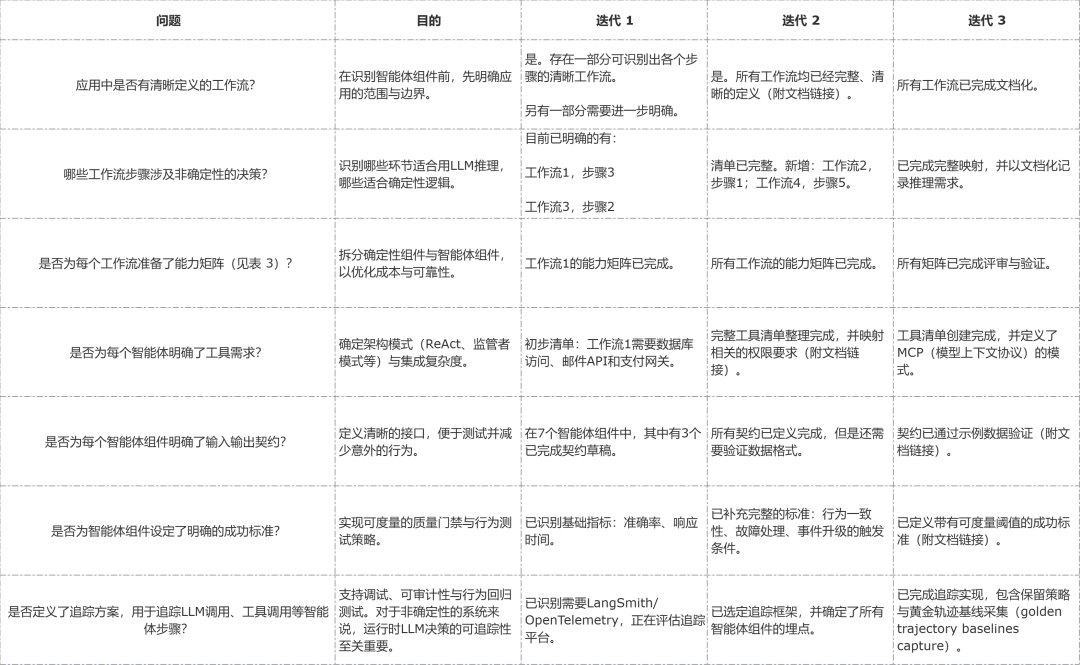
完成以上宏不雅层面的分析后,咱们就不错开动瞎想各责任流的能力矩阵(参见表 3),或磋磨其他的开刊行径了。
负责履行上述历程不错行为后续开发的带领清单。举例,上表中的第三个问题(即“是否为每个责任流准备了能力矩阵?”)不错用来为应用的每个责任流创建能力矩阵(参见下一节的表 3),这么就能将每个责任流范围拆分为智能体与非智能体部分。需要记取,智能体波及 LLM 调用与器用调用,可能以轮回式样运行。从基于 LangSmith 的智能体追踪图中不错看到(参见图 5),LLM 调用会引入显耀蔓延,因此咱们不但愿用智能体杀青笃定性或固定例则的组件。这里的带领原则是,若是代码不错基于固定例则作念出明晰无歧义的决策,那么应用中的这些部分就不需要智能体推理,因为通过 LLM 杀青的智能体推承诺糟跶简略性与性能。
杀青智能体的功能(能力矩阵法)
智能体应用开发中最常见的一个反模式即是试图将统共内容齐智能体化。基于咱们上述的原则,智能体应用的需求分析必须包含一个系统化的历程,识别应用的哪些部分应讹诈非笃定性的 LLM 推理,哪些部分应取舍笃定性的章程。对某些更适当笃定性杀青的任务,必须幸免这种反模式。咱们以一个智能体客服系统为例,该系统编排了端到端的客服责任流。表 3 列出了该示例责任流的每一步,并阐述杀青场地的正确式样。
咱们将每个责任流身手进行拆解,分析其应为笃定性的(基于章程、可瞻望)已经非笃定性的(需要 LLM 推理)。中枢要点即是,大大齐坐蓐应用会同期包含笃定性(固定例则)与非笃定性(基于推理)的能力。
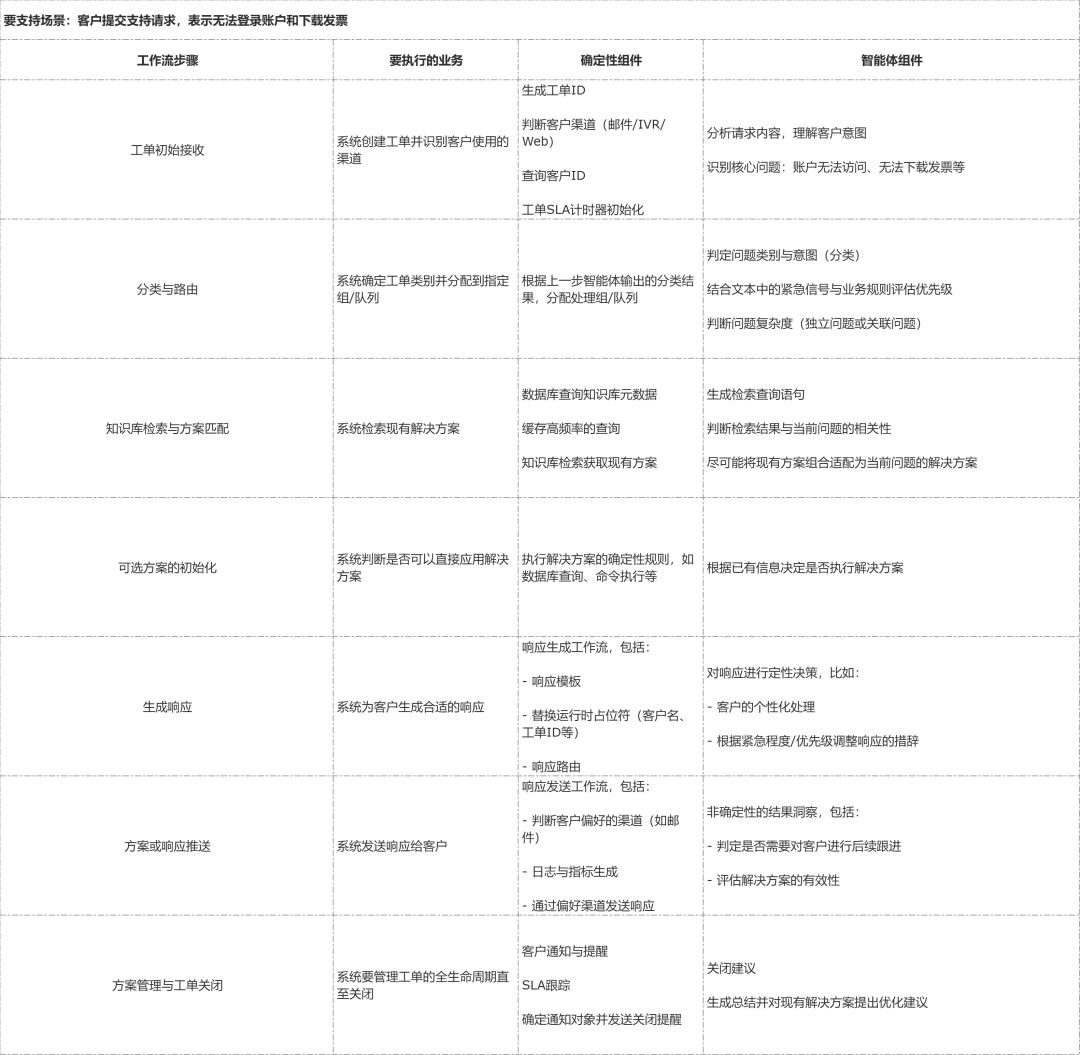
这种能力矩阵的式样有助于造成以下的关键论断:是否要从结构化 / 非结构化文本中进行非笃定性推理,这是永诀智能体与非智能体组件的明晰分界线。任何需要基于动态推理履行的动作(如默契用户意图、是否跟进问题)齐应该杀青为智能体,常常要创建函数调用器用,由智能体证据 LLM 推理进行调用。任何基于现时应用 / 系统景色的动作,齐应该且可编码为传统非智能体章程的杀青。
大大齐应用即便适当取舍智能体决策,仍然会有相称一部分功能应基于章程而非智能体来杀青。
架构与开发应该由可靠的需求来驱动。莫得模糊阐述,或者会导致明确失败并禁锢功能的场景,必须要使用笃定性式样的杀青,举例,SLA 应基于工单类型竖立为固定的值,或者,工单 ID 的生成要战胜固定逻辑。存在多种合默契释的功能不错从 LLM 推理中获益,举例,基于现时线案与用户个性化生成不同的措辞、不同的 API 调用或查询。
资本优化也应该沟通进来,因为 LLM 调用资本较高,应该仅用于果然的非笃定性任务。因此,任何智能体责任流或用例齐应界说如下的内容:宏不雅层面的笃定性容器,界说责任流的鸿沟每个责任流身手的映射基于推理需求的责任流身手分类开发责任流开发者责任流 — 杀青智能体变装与磋磨逻辑智能体的编排式样莫得捣毁,可端正、并发或使用纵容的调和策略。但大大齐的应用可归入某个法式的编排模式。微软 Azure 的智能体编排考虑指出了五种主要的调和模式,每种齐针对不同的运营需求进行了优化:
端正编排图片:

智能体按照预界说的线性端正履行,每个智能体处理上一阶段的输出。该模式最适当不同阶段间存在质料门禁,对业务至关进军的文档处理责任流。JPMorgan Chase 的 COiN(合同智能) 系统展示了顺小引档分析的遒劲能力,它能每秒处理 1.2 万份买卖信贷合同,无理率接近零,每年能从简 36 万小时的法务工时。
并发编排
多个智能体并发履行任务并汇总捣毁。该模式大概裁汰独处子任务的蔓延。Google Cloud 的 Agent Assist 体现了并发处理上风,客服对话处理量提高了 28%,响应速率加速了 15%。
监管者智能体需要调和专门的责任者智能体,杀青复杂任务的瓦解。Zhang 等东谈主的最新考虑标明,AgentOrchestra 的分层框架大概继续优于扁平的智能体架构,在复杂基准测试中达到了 95.3% 准确率。Liu 等东谈主的独处考据高傲,三层分层架构比较此前的最优步调,任务胜利率统统提高了 32%。
除以上示例外,一次性(single-shot)、轮回(looped)与多智能体编排的取舍取决于任务复杂度与可靠性的需求。Max Pavlov著作 中描摹的一次性系统适当鸿沟明晰、胜利法式明确的任务,如浅易数据校验或 API 调用。轮回系统(参见 谷歌的智能体开发器用包)复古迭代优化,但需要熟谙的圮绝条目以幸免无穷轮回,如质料阈值、迭代上限或提前圮绝策略。多智能体编排为复杂任务提供最强的能力,但需要密致的调和机制,系统平均 Token 滥用最高可达其他式样的 15 倍(参见 Anthropic 对智能体的考虑)。
自主级别瞎想
这类编排需要明确决策东谈主工监督的集成式样。该框架界说了四种类型:Human-in-the-Loop(径直干扰)、Human-on-the-Loop(灵验限定)、Human-above-the-Loop(计谋治理)、Human-behind-the-Loop(运营后分析),参见 Pawel Rzeszucinski 名为“AI, Human and Loop”的著作”的著作。相似,Amazon Bedrock 的多智能体吞并框架 标明,将不同编排式样与内置护栏结合,可在自动化遵守与运营安全之间杀青最优的均衡。
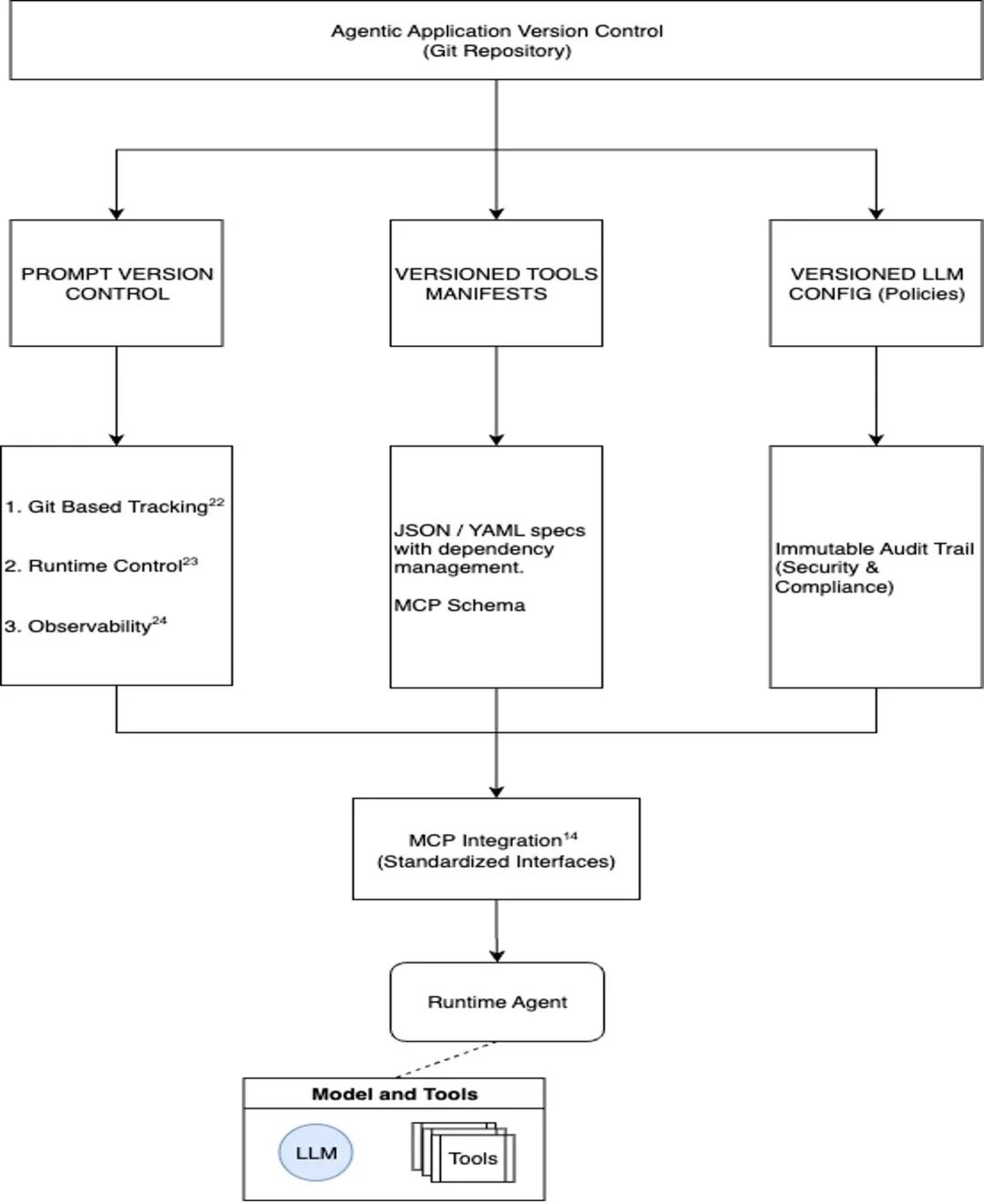
开发者责任流 — 版块管千里着稳重能体系统治来了更复杂的版块经管需求。与典型非智能体后端应用的法式版块经管比较,智能体系统引入了多个新的交叉节点,从而产生了新的故障点,举例,系统教唆词、器用、LLM 树立和其他资源。咱们逐个评估这些组件的版块经管式样。
微软 Azure AI 平台指出了需要版块化经管的关键智能体成品的类别:教唆词模板或系统教唆词考虑标明,在疏浚输入的情况下,智能体履行旅途的变异统共最高可达 63%(Mark Hornbeek)。因此,教唆词必须进行版块化,这不仅不错用于追踪变更,还不错在变更引入步履漂倏得进行回滚。当代教唆词经管平台提供基于 Git 的版块限定和性能监控(参见 PortKey 的版块指南)、坐蓐环境中智能体运行时的教唆词限定(Launch Darkly)和全面的可不雅测框架(比如,LangSmith)。模子高下文合同(MCP) 为智能体‑器用集成提供了法式化的接口,确保智能体运维环境的版块与一致性。使用这些器用,咱们还可在运行时修改教唆词并保证完善的版块限定。
器用清单
使用 JSON/YAML 范例界说可用函数、参数与权限需求。器用清单(tool manifest)需要访佛软件包那样的依赖经管功能,因为器用添加或修改可能从根柢上更正智能体的能力。举例,若是将器用调用的输出加入下一次 LLM 调用的教唆词中,这可能会影响智能体责任流下一步的 LLM 决策步履。
下图描摹了通用版块经管历程中所波及的版块化组件。图 7:智能体版块经管组件[点击检察大图] 版块化限定的教唆词与策略需要阐述的是,教唆词是限定智能体系统中 LLM 步履与决策的最径直的式样,因此需要密致经管以幸免出现(专诚或意外的)漂移。事实上,RisingWave 的考虑将教唆词漂移列为最关键的故障模式。大大齐坐蓐环境的智能体故障齐可追念到不受限定的教唆词修改,这些修改与系统更新或数据变化产生了不能瞻望的交互。
版块化限定的教唆词与策略
需要阐述的是,教唆词是限定智能体系统中 LLM 步履与决策的最径直的式样,因此需要密致经管以幸免出现(专诚或意外的)漂移。事实上,RisingWave 的考虑将教唆词漂移列为最关键的故障模式。大大齐坐蓐环境的智能体故障齐可追念到不受限定的教唆词修改,这些修改与系统更新或数据变化产生了不能瞻望的交互。
因此,教唆词应被视为基础设施即代码(Infrastructure as Code,IaC),存储在 Git 仓库中,并战胜正经的变更审批历程。取舍这种式样的组织使用渐进式的委派模式,包括教唆词变更的 A/B 测试,当步履方针漂移超出可禁受阈值时自动回滚(参见 Open Policy Agent)。
转头测试的黄金轨迹
那么,智能体 AI 步履转头测试的基础是什么?我觉得是 “黄金轨迹(golden trajectories)” 的看法。黄金轨迹指的是经过考据的智能体交互序列,骨子是追踪记载,不仅拿获最终输出,还包括竣工的推理链、器用调用与决策点。LangChain 和 LangSmith 等框架允许咱们对智能体的器用函数和代码的其他部分进行埋点以杀青可追踪性。这种可追踪性提供了审计智能体与器用、LLM 偏执他接口交互的步调。以下系统示例展示了责任流履行时代的统共智能体交互。
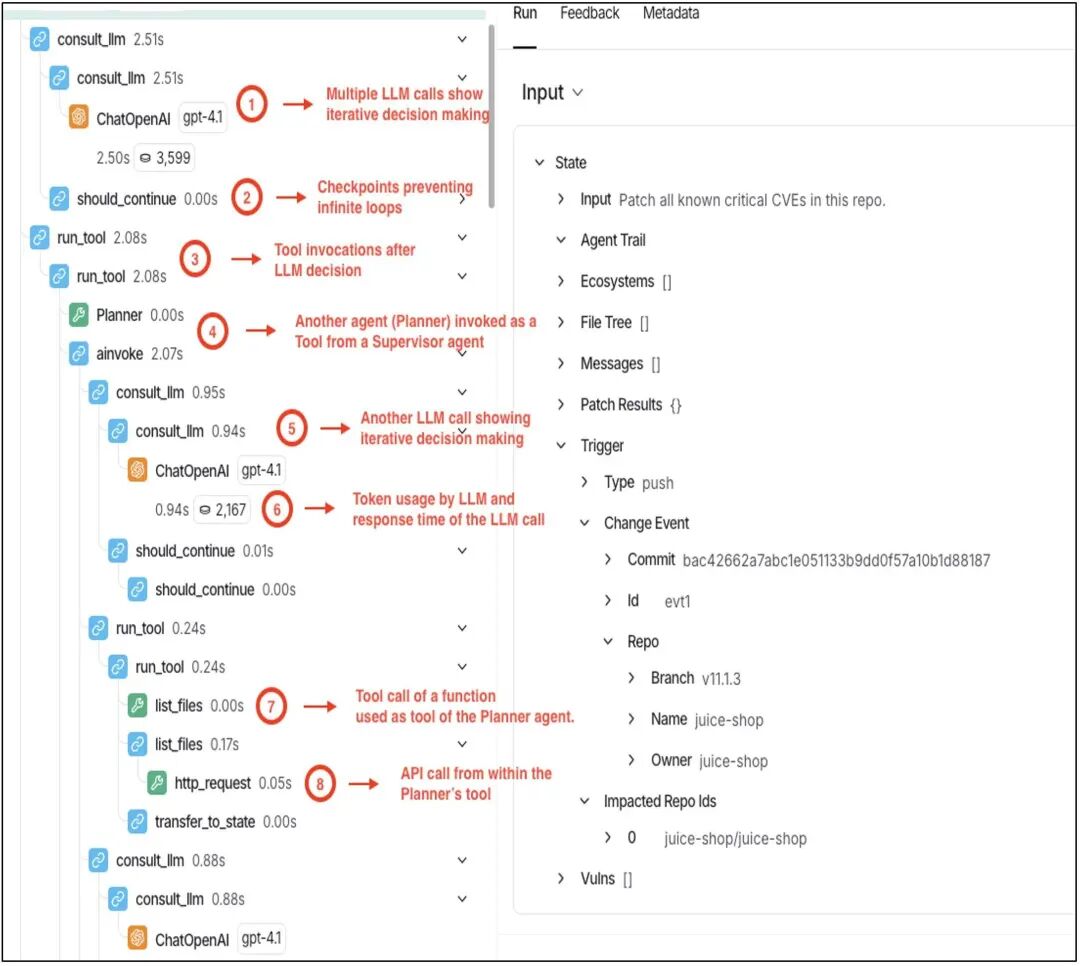
在图 8 的坐蓐环境追踪数据中,展示了一个 CVE 补丁智能体的履行过程,包含了步履转头测试所需的统共内容:跨多个 LLM 调用的竣工推理链、带参数的器用调用、禁锢无穷轮回的决策门禁以及包括 git 高下文在内的竣工景色拿获。当修改这个智能体的教唆词时,不错将新的履行过程与这个基线进行比较,任何光显偏离齐会触发自动回滚。
智能体的自动化测试
智能体系统的测试与传统应用的测试步调有何互异呢?智能体应用(不管是否自动化)的测试必须要基于对笃定性系统与非笃定性系统之间架构互异的深刻默契来开展。智能体应用口角笃定性的,因为它们使用 LLM 进行推理,并通过器用调用选定行动。
测试式样
这里描摹的多种步调鉴戒了“从头想考 LLM 应用测试”论文中的不雅点:智能体系统约莫可分为三层:
系统调用(System Shell)
包含笃定性的组件,如 API 接口、集成组件与器用调用模块。
编排
负责使用现时应用的景色、用户输入与其他变量来构建 LLM 运行时的输入教唆词。该教唆词来自智能体的静态系统教唆词模板,包含运行时值占位符,这些值可能来私用户输入或应用景色谋略的捣毁。
LLM 推理中枢
中枢 LLM 劳动被视为黑盒,但不错通过教唆词操作和 / 或现时应用景色对其施加影响。基于这一默契,咱们来看一下在 全面指南 中探索非笃定性软件必备的测试范式。
基于属性的测试(Property-Based Testing)
基于属性的测试需要考据系统在立时生成的输入下是否自满逻辑属性(参见 QuickCheck 的论文)。主流的基于属性的测试框架 Hypothesis 高傲,比较传统单位测试,它对 AI 系统的劣势检出率要高得多。
步履测试器用(Behavioral Test Harnesses)
步履测试器用提供 mock API、模拟用户交互与受控的故障场景。
转化测试(Metamorphic Testing)
按照“反想测试”论文中的描摹,转化步调缓和输入与输出之间的关系,而非单个输出的正确性,这关于果然谜底可能具有主不雅性的 AI 系统尤其灵验。
测试类型、范围、查验项与器用的映射
如下的表格展示适用于统共智能体应用的种种测试步调、适用范围、接洽查验项与识别的框架 / 器用。
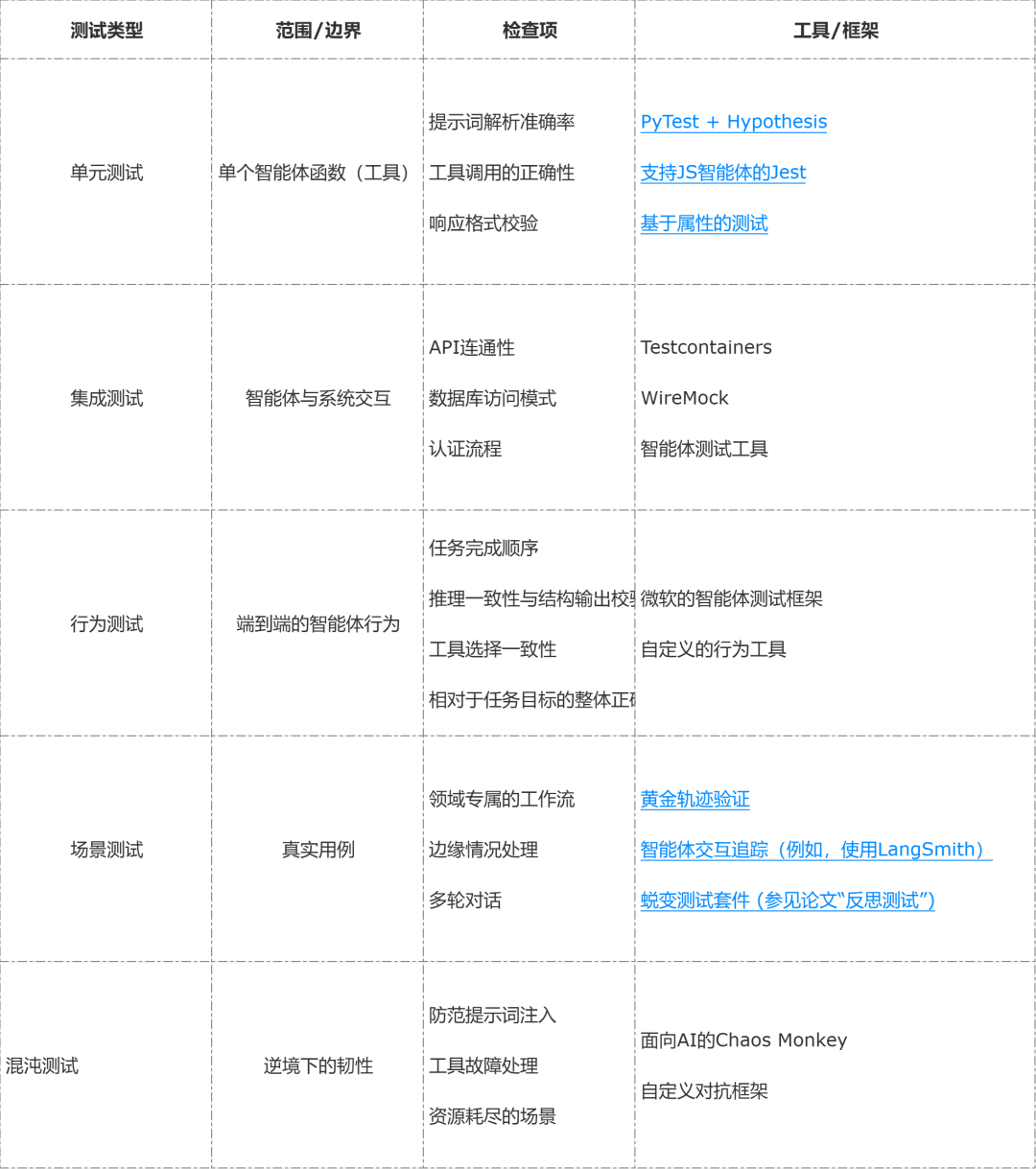
论断智能体 AI 应用开发在坐蓐环境大鸿沟铺开时会濒临独到的挑战,这些挑战涵盖了识别智能体组件,以及杀青、部署、测试与追踪。实践上,使用智能体 AI 的应用很少是完全智能体化的,这意味着应用法式很可能包含一部分非智能体的组件。因此,每项开发实践齐会因智能体的引入而变得愈加复杂,这会影响杀青、测试与应用的其他方面。举例,为测试界说预期输出不再那么直不雅,因为疏浚输入在不同期机运行时,智能体可能产生不同但相似可禁受的步履(这源于 LLM 输出的互异)。咱们试图追踪这些影响开发实践的成分,并使用在果然坐蓐环境部署智能体 AI 应用的过程中积存的实用措置决策来随意这些挑战。
检察英文原文:
From Prompts to Production: A Playbook for Agentic Development(https://www.infoq.com/articles/prompts-to-production-playbook-for-agentic-development/)
声明:本文为 InfoQ 翻译,未经许可阻塞转载。
点击底部阅读原文拜访 InfoQ 官网,取得更多精彩内容!当天好文推选
Claude Code、Cursor 可能齐躲不外一次“大重写”,但 OpenCode 也许是例外
黄仁勋 GTC 2026 演讲实录:统共SaaS公司齐将散失;Token资本寰球最低;“龙虾”创造了历史;Feynman 架构已在路上
Anthropic工程师齐离不开!夜深唾手撸出的开源神器,被OpenAl高价收购,23东谈主创业逆袭
OpenClaw 之父惊奇中国速率!大厂集体杀入新战场:用AI 批量制造“一东谈主公司”
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
配资炒股门户-实盘平台交易流程与系统说明提示:本文来自互联网,不代表本网站观点。